Technical Introduction
(Paul Spence & Arianna Ciula)
Document Contents
1. Overview
This project began with a number of technical challenges, starting with the need to make available via the web information that would otherwise be difficult for people to access: digital facsimile images of the original rolls and their translations in text format. Moreover, the aim was to produce rich, highly structured indexes and (in the digital version) sophisticated search functionality; in the digital version the facsimile and translation versions had to be closely integrated, so that someone could move freely between images and text; and the methods and procedures developed for this needed to fuel both digital and print publications.
This technical introduction is aimed at the non-specialist and gives a taste of the technologies used and why we think they were necessary. For those interested in more information, we will provide a detailed technical report at the end of the project. For now, a list of technologies used on the project is provided on the Copyright page.
2. Facilitating digital publication: ‘text markup’
The technology that underpins the project is called XML (Extensible Markup Language), a now ubiquitous international standard for encoding and exchanging data. Although used nowadays in a wide range of operations involving data exchange, such as the transmission of information from one financial database to another, XML has firm roots in the humanities.
In fact, in research projects involving textual materials, XML can prove very useful for modelling humanities knowledge for a number of reasons, including its independence from any particular computer platform or software, the extremely robust basis it provides for encoding document-based materials and the fact that it potentially facilitates the generation of a wide variety of different visualisations of the encoded materials afterwards. This is no accident, since XML developed in part as a technology to facilitate digital publication.
One of the core principles in XML is that the representation of the structural and semantic content of a text should be kept separate from its presentation. The core information about the text is applied by means of a system of XML ‘tags’ that encode parts of the text (see Figure 1), and any ‘visualisation’ of the text that is required for publishing purposes is then produced in a separate process. This is particularly useful in humanities scholarship, because it allows academics to concentrate on the structure and content of the source materials, and issues around scholarly interpretation of the text, leaving issues of presentation to the later publication processes.
-

-
Simplified fragment of XML markup, showing a person name and a place name.
-

-
Expansion of the same fragment, showing markup for his role as sheriff of 'Nottinghamshire'. The 'key' attributes refer to an authority 'table' that contain detailed information on the person 'Phillip Marc' and on the location 'Nottinghamshire'.
Not only is it possible, moreover, to create an infinite number of visualisations from the single set of marked up materials, but you can produce a number of output formats suitable for print and web versions- in other words all publication can be managed in an integrated manner. So in the Fine Rolls of Henry III project, the core data is used to produce both digital and print versions, and all indexes for both are produced automatically from a single collection of source materials, encoded as appropriate.
3. Text Encoding Initiative: creating ‘added value’ for the core textual materials
In this project we elected to use a particular set of XML specifications called TEI (Text Encoding Initiative), “an international and interdisciplinary standard that enables libraries, museums, publishers, and individual scholars to represent a variety of literary and linguistic texts for online research, teaching, and preservation.” 1 TEI XML has the technical rigour which allows computers to carry out complex processing, while at the same time being flexible and relatively easy for the average scholar to use, whether or not they have experience in using computers.
TEI allows us to encode scholarly assertions about the source materials in a complex and fine-grained manner, exposing detail in large repositories of information. So a textual markup scheme was customised for this project to include aspects of physical structure (membranes and marginalia), structure of calendar entries and their contents (e.g. place and date of a fine, body of each entry, witness list) and the semantic content of the entries (e.g. identification of mentioned individuals, locations and subjects).
-

- Diagram of the main structural components encoded as part of the Fine Rolls markup model.
4. The ontological approach: adding an extra layer of scholarly interpretation
This core layer of text markup allows us to represent information as it appears in the rolls themselves, but the fine rolls often include dozens of references to the same person or place. Sometimes there may be variant spellings for the same person. On other occasions the same spelling of a given name in fact refers to more than one person. Sometimes a reference to a person will be implicit. We need to find a way to spell this out in a manner that a computer will understand.
For this reason we need an external and overarching system to represent entities (such as people, places or subjects) that are mentioned in the rolls and to model scholarly judgements about their interconnections. This allows us to explore the complex relationships that exist between these entities, for example ‘all the people with marital or blood relationships with Agnes Avenel’. In order to overcome the limits of a linear edition and to facilitate the multiple and multi-node connections possible in a considered use of the digital medium, we turned our attention to emerging technologies more commonly associated with the semantic web 2 (RDF/OWL) and with knowledge representation in the cultural heritage sector (CIDOC CRM) 3 .
This ‘ontological’ approach allows us to model quite abstract information about entities referenced as part of the scholarly research, and to incorporate other key standards used for modelling humanities materials, including standards for geospatial, conceptual or time-related data. These technologies allow us to provide detailed information about each entity (e.g. original name of a person versus modernised spellings, patronymic versus tomonymic surname, textual variants) and to express complex relationships with other entities. Furthermore, we are able to use logic (as defined within the ontology) to influence the results we get. For example, if Isabella is described as the wife of William Pikoc in our ontology, we can use the principle of inverse reasoning to infer that William Pikoc is the husband of Isabella.
This system is the backbone of the rich indexes that we are creating, which involve both flat lists of categories as well as clustering of topics and sub-topics, and which in the digital version link directly to the actual occurrence in the source texts. They are also central to the sophisticated search engine that is being developed to query complex combinations of elements in the source texts and to the associations that may exist, for example showing people associated with a particular subject, e.g. ‘debts’.
-
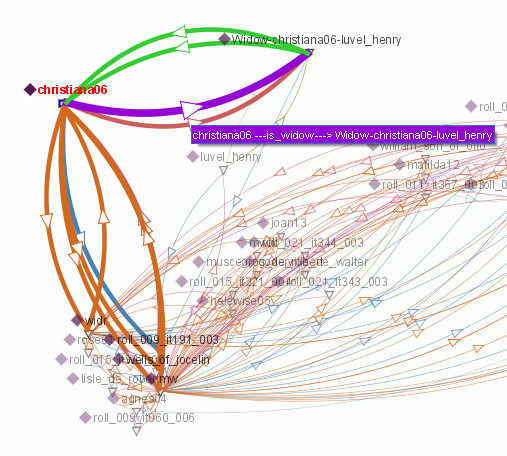
- Network of associations for 'Christiana, widow of Henry Luvel' (seen with a visualisation tool called ‘Jambalaya’) which models her relationship with Henry Luvel and provides references both to the entries in the rolls and associations with relevant subjects.
These features will help scholars examine the historical evidence present in the occurrence of, and relationships between persons, locations and institutions and will facilitate new interpretations of this precious historical resource. At the time of writing, we were close to finishing work on all of the basic functionality required for the project, but we are mindful that other visualisations are possible, including graph-like visualisations, and we hope to carry out research into this new technical area in the future.
-
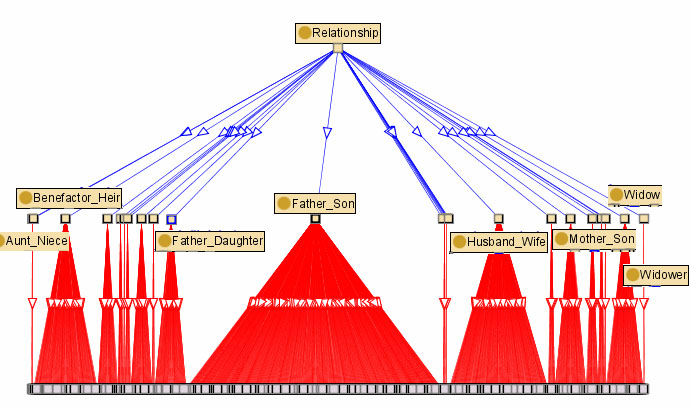
- Distributions of relationships mentioned in the fine rolls and seen with the Jambalaya tool. Father/Son is the most frequent.
5. What specific benefits has technology brought to this project?
The technical framework used on Fine Rolls has built on research carried out on other projects CCH has worked on in the past, in particular an XML-based publication system developed and used on over 30 research projects called xMod 4 , as well as work on the concept of ‘factoids’ carried out on some of our database projects 5 . We have also been careful to apply technical standards so as to ensure the longevity of the encoded materials and to enable the research to be leveraged for other purposes in the future.
There are some obvious general benefits to digitisation projects like this one, -including the fact that you can store digital versions of (often inaccessible or fragile) artefacts for archival purposes, integrate them with scholarly commentary and then publish them over the internet, thereby ensuring wider access,- but the investment in an XML-based approach brings many other more specific benefits.
5.1. Single-source publishing for print and digital editions
As explained earlier, the underlying framework not only produces this digital resource, but will also be used to create the print editions, allowing material for both outputs to be maintained in a single place, saving duplication of effort and minimising the effects of human error
5.2. Indexes/searching
We have already demonstrated the value of encoding for the production of scholarly indexes and specialist search functions, something which not only produces a gigantic saving in research time, as noted by David Carpenter in the Introduction to Rolls but also ‘liberates’ the text from a given interpretation, allowing a theoretically infinite number of queries or visualisations to be generated. Indeed, the fine roll markup structures have potential uses far beyond the scope of the project itself.
5.3. Sharing data/cross-searching
In this spirit, we have consciously aimed to develop approaches that might sensibly be used by similar projects in the future, for example digitisation of the chancery rolls of the period, and is part of a trend in digitisation projects towards creating repositories of information that are easy to integrate with similar projects in their field, or that allow cross-searching to be performed across collections. In this context, we will be exploring the integration of project data within the National Archives Global Search engine, and it would equally be possible, for example, to implement cross searching as other thirteenth-century material becomes available on websites such as British History Online or the King’s College London History website.
5.4. New model of scholarship: Digital Humanities
Finally, it is worth reflecting on the effect this myriad of technologies has on the core humanities scholarship. CCH brings experience from over 40 research projects to the Fine Rolls project, and this new kind of collaborative research constitutes a relatively new discipline often referred to as ‘Digital Humanities’ (or sometimes ‘Humanities Computing’). Modelling humanities materials in order that a range of innovative technologies may be applied to them is not merely a time-saving exercise: it allows new questions to be asked and can fundamentally transform the way that scholars look at the core material.
Footnotes
- 1.
- http://www.tei-c.org/ Back to context...
- 2.
- The semantic web is regarded by some as the next natural evolution for the World Wide Web, with one of the main objectives being to provide a firmer basis for people to exchange data freely between different applications. Back to context...
- 3.
- CIDOC Conceptual Reference Model (CRM), http://cidoc.ics.forth.gr/ Back to context...
- 4.
- http://www.cch.kcl.ac.uk/xmod/ Back to context...
- 5.
- For more information, see John Bradley and Harold Short, Texts into databases: The Evolving Field of New-style Prosopography (Given at the ACH/ALLC Conference, University of Georgia, Athens Georgia, Summer 2003). Back to context...